Mikhail Naganov
rvalue references and move semantics in C++11, Part 2
Continued from Part 1.

Previously we have seen that the compiler can match functions accepting
rvalue reference arguments to temporary values. But as we have discussed
before, it also helps for program efficiency to avoid copying when the
caller abandons ownership of an object. In this case, we need to treat a
local variable as if it were a temporary. And this is exactly what
std::move function is for.
On the slide example, there are two overloads for the function
foo: one for lvalue references, and one for rvalue references. The
calling code prepares a string, and then transfers ownership to the
callee by calling std::move on the variable. The agreement is that
the caller must not use this variable after calling std::move on it.
The object that has been moved from remains in a valid, but not
specified state.
Roughly, calling std::move on a value is equivalent to doing a
static cast to rvalue reference type. But there are subtle differences
with regard to the lifetime of returned temporaries stemming from the
fact that std::move is a function (kudos to Jorg Brown for this
example). Also, it’s more convenient to
call std::move because the compiler infers the return type from the
type of the argument.

There are well known caveats with the usage of std::move.
First, remember that std::move does not move any data—it’s
efficiently a type cast. It is used as an indication that the value will
not be used after the call to std::move.
Second, the practice of making objects immutable using const keyword
interferes with usage of std::move. As we remember, rvalue reference
is a writable reference that binds to temporary objects. Writability
is an important property of rvalue references that distinguish them from
const lvalue references. Thus, an rvalue reference to an immutable value
is rarely useful.

This one I see a lot of times. Remember we were talking that expressions have two attributes: the type and the value category. And that an expression which evaluates a variable has an lvalue category. Thus, if you are assigning an rvalue reference to something, or passing it to another function, it has an lvalue category and thus uses copy semantics.
This in fact makes sense, because after getting some object via an
rvalue reference, we can make as many copies of it as we need. And then,
as the last operation, use std::move to steal its value for another
object.

And finally—sometimes people want to “help” the compiler by telling it that they don’t need the value they are returning from function. There is absolutely no need for that. As we have seen earlier, copy elision and RVO were in place since C++98.
Moreover, since calling std::move changes the type of the value, a
not very sophisticated compiler can call a copy constructor because now
the type of the function return value and the type of the actual value
we are returning do not match. Newer compilers emit a warning about
return value pessimization, or even optimize out the call to
std::move, but it’s better not to do this in the first place.

We have discussed how use of move semantics improves efficiency of the code by avoiding unnecessary data copying. Does it mean that recompiling the same code with enabled support for C++11 and newer standards would improve its performance?
The anwer depends on the actual codebase we are dealing with. If the code mostly uses simple PODs aggregated from C++ standard library types, and the containers are from the standard library, too, then yes—there can be performance improvements. This is because the containers will use move semantics where possible, and the compiler will be able to add move constructors and move assignment operators to user types automatically.
But if the code uses POD types aggregating primitive values, or homebrew containers, then performance will not improve. There is a lot of work to be done on the code in order to employ the benefits of move semantics.

In order to consider the changes between C++98 and C++11 in more detail, I would like to bring up the question of efficient parameter passing practices. Those who programmed in C++ for long enough know these conventions by heart.
On the horizontal axis, we roughly divide all the types we deal with into three groups:
- cheap to copy values—small enough to fit into CPU’s registers;
- not very expensive to copy, like strings or POD structures;
- obviously expensive to copy, like arrays; polymorphic types for which passing by value can result in object slicing are also in this category.
On the vertical axis, we consider how the value is used by the function: as an explicitly returned result, as a read only value, or as a modifiable parameter.
There is not much to comment here except for the fact that unlike the C++ standard library, the Google C++ coding style prohibits use of writable references for in/out function arguments in order to avoid confusion.

What changes with C++11? Not much! The first difference is obvious—C++11 gets move semantics, thus functions can be overloaded for taking rvalue references.
The second change is due to introduction of move-only types, like
std::unique_ptr. These have to be passed the same way as cheap to
copy types—by value.
Then, instead of considering whether is a type is expensive to copy, we
need to consider whether it is expensive to move. This brings the
std::vector type into the second category.
Finally, for returning expensive to move types, consider wrapping them into a smart pointer instead of returning a raw pointer.

As a demonstration of why it’s now efficient to pass vectors by value, let’s consider the case when copy elision is not applicable due to dynamic choice of returned value.
In C++98, this code results in copying the contents of the local vector, this is obviously inefficient.

However, a C++11 compiler will call a move constructor in this case. This demonstrates why a type with efficient move implementation can always be returned by value from functions.

Let’s return to our slides explaining different ways of passing data between functions. In C++98, it makes no difference for the caller how the callee will use a parameter passed by a const reference. For the caller, it only matters that it owns this data and the callee will not change it.
If we consider the callee implementation, if it’s possible for it not to make a copy of the data, it’s likely a different action or algorithm from the one that requires making a copy. I’ve highlighted this difference on the slide by giving the callee functions different names.
And we have no performance problems with the function that doesn’t need
to make a copy—function B. It’s already efficient.
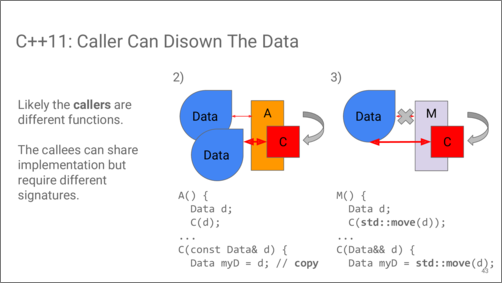
C++11 can help us with the second case. Now we can prepare two versions of the callee: one for the case when the caller can’t disown the data, and one for the case when it can. Clearly, these callers are different now, that’s why they are given different names on the slide.
In the first case we still need to make a copy, but in the second case
we can move from the value that the caller abandons. It’s interesting
that after obtaining a local value, it doesn’t really matter how it has
been obtained. The rest of both overloads of the function C can
proceed in the same way.
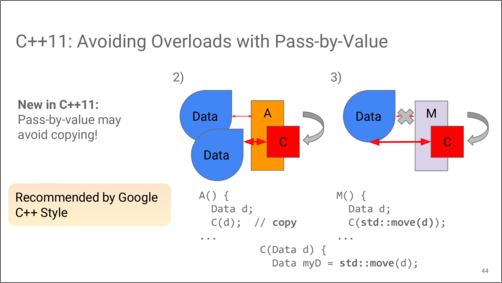
Which brings us to the idea that we can unify these two overloads, and require the caller to either make a copy, or to transfer ownership for the value it used to own.
This relieves us from the burden of writing two overloads from the same function. As you can see, the call sites do not change!
In fact, this is the approach that the Google C++ Style Guide highly recommends for using.

This idiom doesn’t come for free. As you can see, there is always an additional move operation that happens on the callee side.
And since the copy operation now happens at the caller side, there is no way for the callee to employ delayed copying.
However, the pass-by-value idiom works very nicely with return-by-value, because the compiler allocates a temporary value for the returned value, and then the callee moves from it.

Since using pass-by-value idiom apparently has costs, why does the Google C++ Style Guide favors it so much?
The main reason is that it’s much simpler to write code this way. There is no need to create const lvalue and rvalue reference overloads—this problem becomes especially hard if you consider functions with multiple arguments. We would need to provide all the combinations of parameter reference types in order to cover all the cases. This could be simplified with templates and perfect forwarding, but just passing by value is much simpler.
The benefit of passing by value also becomes clear if we consider types that can be created by conversion, like strings. Taking a string parameter by value makes the compiler to deal with all the required implicit conversions.
Also, if we don’t use rvalue references as function arguments, we don’t need to remember about the caveat that we need to move from them.
But we were talking about performance previously, right? It seems like we are abandoning it. Not really, because not all of our code contributes equally to program performance. So it’s a usual engineering tradeoff—avoiding premature optimization in favor of simpler code.

Does it mean we can apply pass-by-value idiom to any code base? The answer is similar to the one that we had on the “silver bullet” slide. Apparently, that depends on whether types in your codebase implement efficient move operations.
Also, applying this idiom to an existing code base shifts the cost of copying to callers. So any code conversion must be accompanied with performance testing.
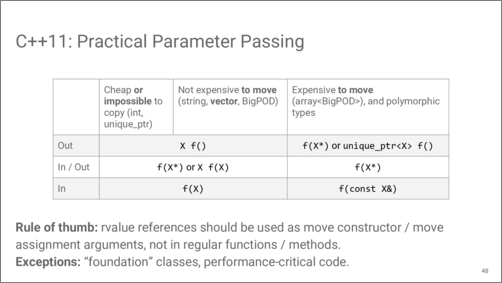
Having pass-by-value in mind, let’s revise our table with recommended parameter passing. Types that can be moved efficiently, can be passed by value both as in and out parameters. Also, instead of passing an in/out parameter using a pointer, you can pass it as an input parameter, and then get back as an out parameter, both times by value.
Expensive to move and polymorphic types should still use pass-by-reference approach.
As you can see, there is no place for rvalue reference arguments here. As per Google C++ Style guide recommendations, they should only be used as move constructor and move assignment arguments. A couple of obvious exceptions are classes that are have a very wide usage across your codebase, and functions and methods that are proven to be invoked on performance critical code paths.

So we have figured out that we need to know how to write move constructors and move assignments. Let’s practice that.
There is a trivial case when a compiler will add move constructor and move assignment automatically to a structure or a class, and they will move the fields. This is possible in the case when the class is a trivial POD, and doesn’t have user-defined copy constructor, copy assignment operator, and destructor.
For this example, I’ve chosen a simple Buffer class—we do use a lot of buffers in audio code.
Let’s start with the class fields and constructors. I’ve made is a
struct just to avoid writing extra code. So we have size field, and a
data array. To leverage automatic memory management, I’ve wrapped the
data array into a std::unique_ptr. I’ve also specified the default
value for the size field. I don’t have to do that for the smart
pointer because it’s a class, thus the compiler will initialize it to
nullptr.
I defined a constructor that initializes an empty buffer of a given
size. Note that by adding empty parenthesis to the array constructor you
initialize its contents with zeroes. I marked the constructor
as explicit because it’s a single argument constructor, and I don’t
want it to be called for implicit conversions from size_t values.
Note that I don’t have to define a destructor
because unique_ptr will take care of releasing the buffer when the
class instance will get destroyed.
And we don’t have to write anything else because as I’ve said, the
compiler will provide a move constructor and a move assignment operator
automatically. But it will not be possible to copy an instance of this
class because unique_ptr is move-only.

So let’s define and implement a copy constructor. It takes a const
reference to a source instance. I use a feature of C++11
called delegating constructor, which allows me to reuse the
allocation code from the regular constructor. After allocating the data
in the copy recipient, I copy the data from the source. Note that a call
to std::copy with all parameters being a nullptr is valid, thus
we don’t need a special code to handle copying of an empty buffer.
In this case the compiler does not add move constructor and move assignment by itself. And that means, any “move” operations on this class will in fact make a copy of it. That’s not what we want.
So, we tell the compiler to use the default move assignment and move constructor. These will move all the fields that the class has. Also simple.

By the way, we haven’t provided a copy assignment yet. The compiler generates a default version, but suppose we need to write one by hand.
This is one of the idiomatic approaches, it’s
called copy-and-swap.
I’ve seen it mentioned in early S. Meyers’ books on C++. We make a copy
of the parameter into a local variable—this calls the copy constructor
we have defined earlier. Then we use the standard swap function to
exchange the contents of the default initialized (empty) values of our
current instance with the copy. As we exit the function, the now empty
local buffer will be destroyed.
The advantage of this approach is that we don’t need to handle self-assignment specially. Obviously, in case of a self-assignment there will happen an unneeded copying of data, but on the other hand, there is no branching which is also harmful for performance.

Now suppose we also want to implement a custom move assignment. A naive attempt would be to use the same approach as for copying. In a move assignment we receive a reference to a temporary, so we could swap with it.
Unfortunately, we are creating an infinite loop here, because the
standard implementation of the swap function uses move assignment
for swapping values! That makes sense, but what should we do instead?

In order to break the infinite loop, we need to implement the swap
function for our class. In fact, this function is implemented by
virtually any C++ standard library class.
Note that it takes its in / out parameter by a non-const reference. This is allowed by the Google C++ Style Guide specifically for this function, because it’s a standard library convention.
It’s important to mark this function as noexcept because we will use
it in other noexcept methods.
The implementation of this function simply calls the swap function
for every field of the class. As I’ve said, this functions is defined
for all language types and C++ standard library classes, so it knows how
to perform swapping of values having size_t and std::unique_ptr types.
Note that the idiomatic way to call the swap function is to have the
using std::swap statement and then just say swap, instead of
calling std::swap directly. This is because this pattern allows to
call user-defined swap functions. The full explanation is available in
the notes on Argument-dependent
lookup.

We also define an out-of-class swap function which takes
two Buffers and swaps them.
Note that adding the friend keyword makes this function to be an
out-of-class, even if we declare and define it within our class
definition.

Now we can implement move constructor and the move assignment trivially
using the swap function. A move constructor is simply a call to
swap. A move assignment must in addition return a reference to our
instance. Both functions are marked noexcept.

In fact, by employing pass-by-value, we could merge the implementations of copy assignment and move assignment into one function as demonstrated here. This is called a “unified” assignment operator.
As we have discussed before, this implementation costs an additional move operation. Also, the copying now happens at the caller side. Maybe not the best approach for a class that will be used widely.

Here is the complete code for the class, and it fits on one slide. As you can see, writing simple classes that support move semantics is simple. But as usual with C++ you have an infinite number of alternatives to choose from.

What I have explained to far, were basics. It’s very important to understand them before going any further.
And when you are ready to, here are some references. I’ve used these materials while preparing this talk. The first is the Scott Meyer’s book on effective modern C++ techniques—it contains an entire chapter on rvalue references and move semantics. Then it’s the Google C++ Style Guide which I was quoting often in this talk. It provides sensible guidelines that help writing understandable code. Abseil library C++ tips contain a lot of explanations and examples on not so obvious behavior of C++. Thomas Becker’s article is a good place to dive into rvalues and move semantics details. The “Back to Basics!” talk by Herb Sutter contains interesting discussions regarding the C++11 and C++14 features.
And, for getting more insight into C++ history, and into the history of rvalue references and move semantics, there is the Bjarne Stroustrup’s book, and the original proposals to the standard.