Mikhail Naganov
Understanding Git, Part 1
This is the transcript of the talk about Git version control system that I have presented to my colleagues. The talk consists of 3 parts, in this post I’m publishing the first one.

Welcome to the talk about Git. Git is the tool we use every day. Still, Git can remain a mystery to lots of people, and they resort to “cookbook” approach, using Stack Overflow as a translator between their needs and Git commands. This isn’t surprising because Git is really complex—every command in it is a Swiss army knife which can do lots of things. Because of that, the description of each command’s parameters usually takes several pages. And what’s worse, the help pages assume that the reader is familiar with how Git works and use Git-specific jargon extensively, making things even more confusing.

The purpose of this talk is to demystify Git, the goals of the talk are listed on this slide. We start by explaining from a high level what Git repository is built from and how its parts are connected. This will help understanding the role of each command, how to apply the commands to everyday tasks, and how to get out of trouble.

We start with understanding the building blocks of a Git repository. Quoting Fred Brooks, “Show me your data structures, and I won’t usually need your code; it will be obvious.” In this description we stay away from Git commands in order to concentrate on abstract properties of the data they operate on.
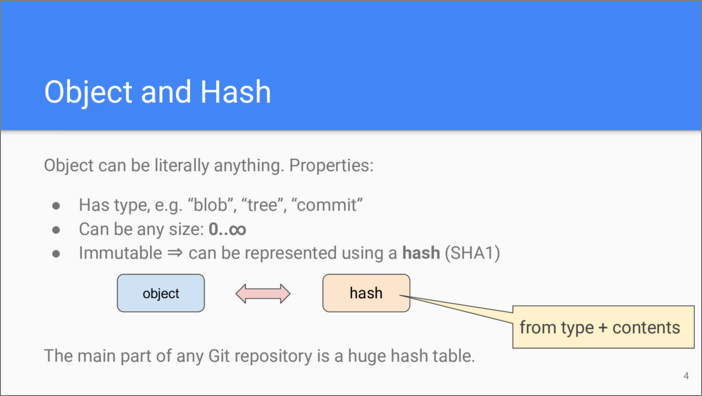
At the storage level Git is only interested in the contents of objects and their type. Git repository is a content-addressable storage. Each object is immutable and is permanently referenced by the SHA1 hash calculated from its type and contents. Git uses file system as an index, making it easy to find an object by its hash. Effectively, Git repository is a huge hash table.
Git itself doesn’t impose any restrictions on the size of objects. But usually there are practical limitations from the underlying file system.
Does an object with no content even make sense? Yes, it does. For example, we might need to store an empty file in Git repository. The interesting point is that since the type of the object is added to the content in order to produce the hash, every empty object of each type has a distinct hash.
UPDATE on SHA-1 and collisions: Linus noted a long time ago (in 2006) that having a collision is unlikely in the lifetime of the Universe and shouldn’t be a big problem. However, as clever engineers from Google have demonstrated it is possible to create a SHA-1 collision deliberately. Following this result, GitHub has added measures to detect them (but they admit you need to have huge resources in order to generate such a collision). The Git project is working on a transition from SHA-1 to SHA-256 hash function. The release notes for Git 2.24 says “Preparation for SHA-256 upgrade continues.”
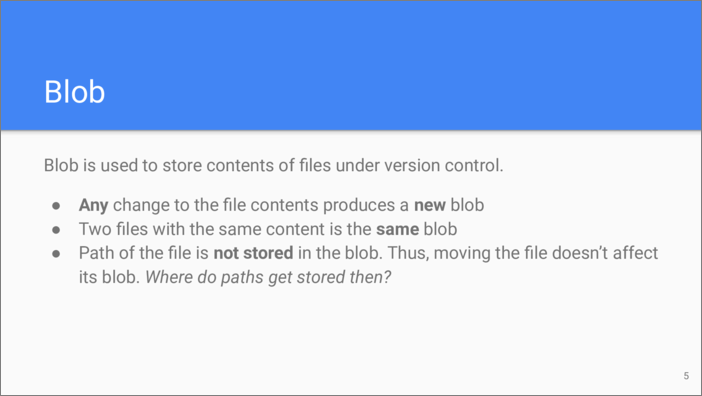
Blob is the simplest type of Git object. It stores the contents of a file. Due to the principles of objects storage explained above, changing even a character in a file produces another blob. Because the path and the name of the file is not stored in the blob, two files with the same content are indistinguishable at the storage level and occupy the same blob. However, this also means there should be a way for finding a file from its name and path.
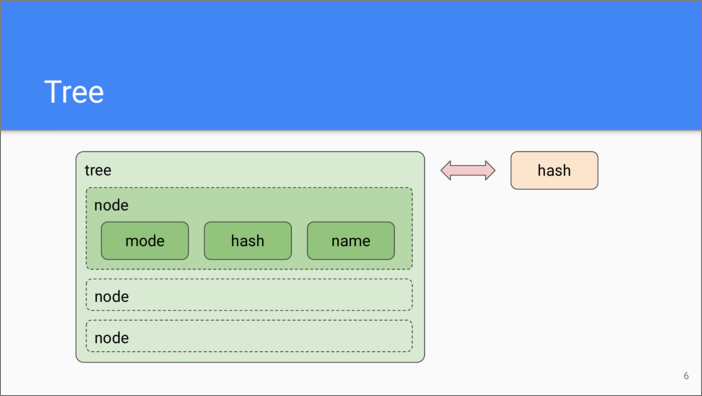
This is what tree objects are for. Each tree object corresponds to a directory in the file system. The tree object consists of nodes. In the simplest case a tree can be empty and have no nodes at all. If it does have them, each node stores a name, file system mode, and the hash of the object. Since trees are stored as objects, they have associated hashes, too. Thus, a hash in the node entry typically points out either to a tree object or to a blob object.

This is an example of a tree object. The leftmost column is the file system mode which uses traditional UNIX octal constants, then we see the object type which is in fact extracted from the object contents. The contents are accessed by the hash listed on the next column. The rightmost column is the object name in the file system.
On this slide we see how a tree object references a blob and another tree object.
UPDATE: Note that since multiple directories and multiple files from the file system with the same content will “collapse” into the same tree or blob object in Git’s repository, tree nodes actually create a graph structure—there can be multiple paths from the top level tree object to a leaf node.

From these explanations we can conclude that Git always stores full contents of each file and directory. And every stored change to the project is like a snapshot of the working directory. Git doesn’t store deltas between file states as some other version control systems do.
This model may appear wasteful, but as a change doesn’t typically modify all the files, it’s actually not that bad. Also, underneath the storage model Git uses compression to save space. The benefit of this model is that if we take a top-level tree object of a snapshot, we can very quickly restore our working directory to that state.
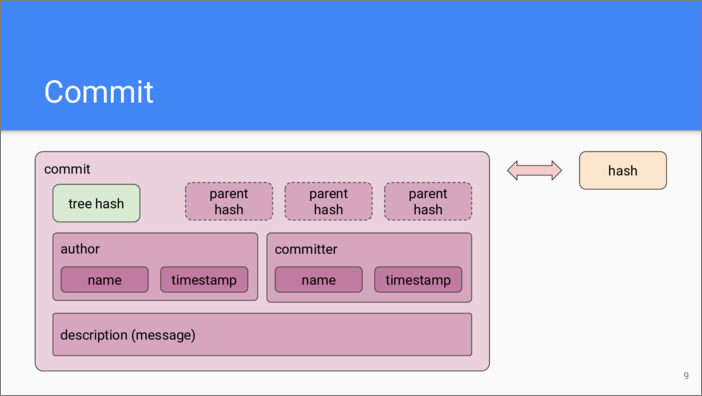
Each change is stored by Git as a commit object. This is a richer object than previous two. A commit stores a hash of the top-level tree object of the snapshot. It also stores information about the change: who and when prepared it, and who and when committed it into the repository, along with a human-readable description of the change, which is often called a “commit message”.
As a Git object, a commit also has a hash. Each commit stores 0 or more entries to previous commits called “parent commits”. This arranges commits into a directed graph.
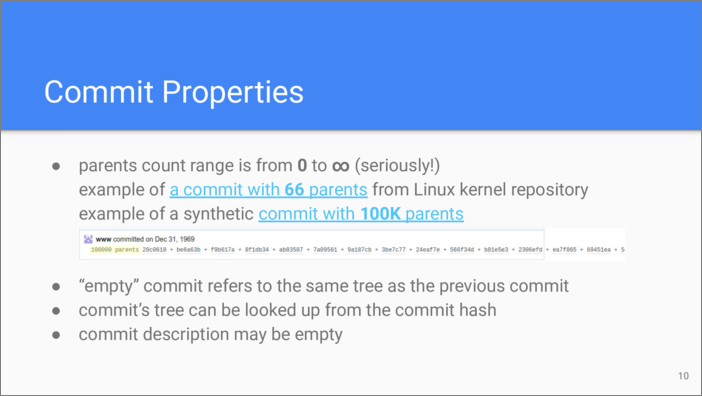
Git doesn’t impose any restrictions on the number of parents that a commit may have. Linux kernel repository has a famous commit with 66 parents. A less practical example on GitHub shows a commit with 100,000 parents. Again, the restrictions here typically result from the size of the commit object as a file in the filesystem and the time that is needed to process commit objects.
Speaking of other “edge cases” of commits, they may have no parents, too. For example, the very first commit in the repository doesn’t have a parent.
Yet another “edge case” is when two subsequent commits refer to the same tree. That means that the later commit doesn’t really have any changes compared to the previous one. It is called “an empty commit”.
Note that since each commit always contains one reference to a tree, operations on trees can accept commit hashes and trivially resolve a commit into the corresponding tree.
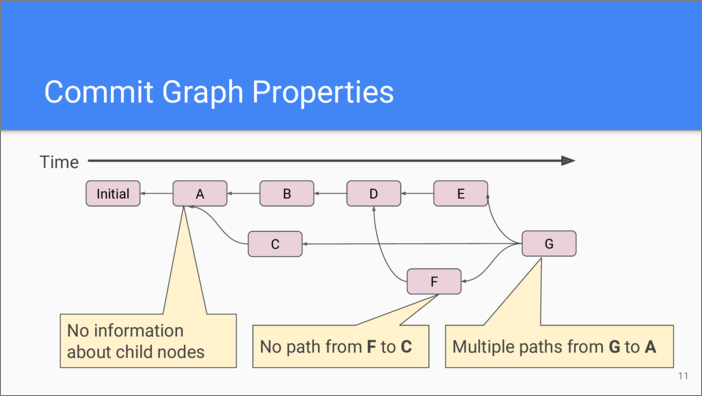
Let’s examine the commit graph more closely. It’s a very important structure in the repository. As we have seen before, more recent commits refer to older commits as their parents. There are no back references though, so traversing commits in a forward chronological order is not efficient.
The crucial relationship between the commit graph nodes is whether one commit is reachable from another—that is, whether there is a path from one commit to another. Since a commit can have multiple parent nodes it’s possible to have multiple paths. Obviously, the initial commit is reachable from every node of the commit graph.

For some tasks it’s efficient to organize commits into a list. The list can order the commits in arbitrary ways, and even gather together commits that are not reachable from each other in the commit graph.
Lists help in disambiguating graph navigation. For the provided graph example, if we say “go 3 commits back from the commit G”, since the commit “G” has multiple parents, there are multiple paths to follow. But if we provide a list, there are no doubts what we have meant.

A lot of git commands operate on the commit graph. It’s important to understand what operations can be executed on it. As we mentioned earlier, the most important operation on the commit graph is finding paths between two commits. Very often we are looking for a path between some commit and the initial commit— such a path always exists.
The path can be represented as a list of commits. Then the list of commits can also be considered as a set—as there are no cycles in the commit graph, any commit can only occur in the path once. Then we can apply the usual mathematical operations to this set: finding a complement of the set and performing usual operations on two sets: combining them, intersecting, and finding commits that present in one set, but not in another.
There is also once particular operation which is useful for version control—if we have two paths going from commits “A” and “B” to the initial commit, it’s obvious that they will share a subpath. If we want to exclude these shared commits from our consideration, we make a union of the path differences. In mathematics, this operation is called “symmetric difference”.
Finding a path doesn’t change the graph. The only way we can change the graph is by adding another node to it. I’m sure you have used “amend” and “rebase” commands in Git, and it might look as if you are modifying a commit. Understand that in fact you create new commit or commits.
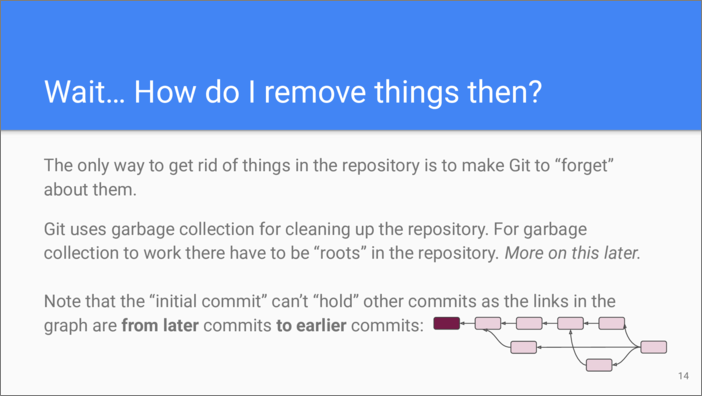
Sure enough, this approach raises a question on efficiency. If commits can only be added, how to prevent an unbounded growth of our repository? Git manages that using garbage collection technique. There exists a set of garbage collection “roots”. They comprise what the repository users do care about. Objects that are not reachable from the roots are considered garbage.
Please note that since the commit references go backward in time, the initial commit doesn’t “hold” any other commit, in fact the opposite is true.

Let’s consider another thing specific to version control systems—patches (or diffs). As I’ve mentioned before, Git doesn’t store patches in the repository, but generates them as needed. Typically the patch is generated by comparing 2 tree objects. What do patches consist from?
The core of the patch is the sequence of modifications done to the files. First, the file itself can be renamed, added, or removed. Second, there can be modifications to the contents of the file. Each modification is a sequence of so called “hunks”.
An optional part of the patch is the change description. In the trivial case, the patch can be empty.
Note that since patches are not stored in the Git repository, they don’t have hashes.
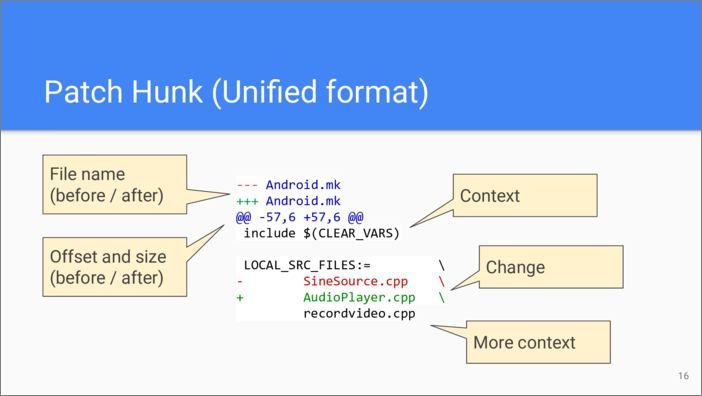
What is a patch hunk, exactly? Git uses so called “unified format” for patches, and this is how a hunk looks like. Before the hunks, there come two lines that contain the old file name and the new file name. Each hunk starts with the line that specifies the line number when the old text starts and the length of the part being modified. Then there is the new line number—it can change because the previous hunk has added or deleted some lines—and the new length.
The change always stores the context—the surrounding lines, as a measure to prevent garbling up the file if it was changed since the patch was generated. The change itself is represented by lines being removed and the lines being added.

As with the commit graph, we can also apply mathematical thinking when considering patches and come up with a “patch algebra”.
For each patch, we can produce its inversion—if we apply the patch and then its inversion, there will be no changes to the file. We can split a single patch into a series of smaller patches. We can also combine them back into the original patch. If we have a sequence of patches, we can change their order, which will in general require changing the patches.
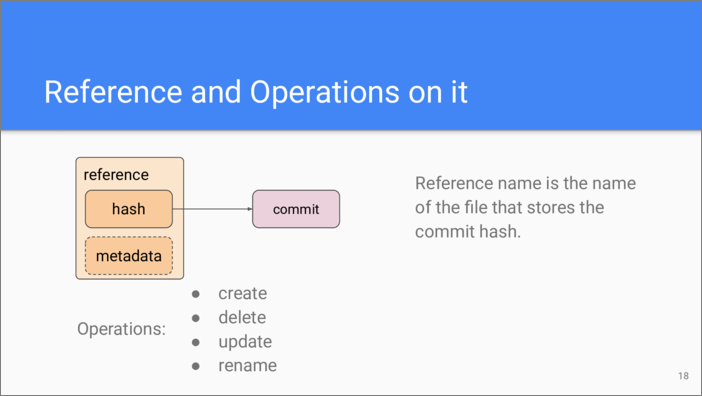
The last building block we are considering is a reference. It’s a very simple object which typically only holds a commit hash. References are not stored in the repository hash table and don’t have an associated hash. Instead, references are stored as files in the file system, and the file name is the reference name—everything is simple here. Sometimes references have associated metadata.
Usual file operations can be applied to a reference, including updating the commit hash that it stores.

Conceptually, references live on a different abstraction layer. They provide entry points into the graph, giving human-readable names to commits. We can thus use reference names instead of trying to memorize commit hashes.
One of the usages for references by Git is for managing development branches. The “master” branch (or reference) is created by default, but there is actually nothing special about it.
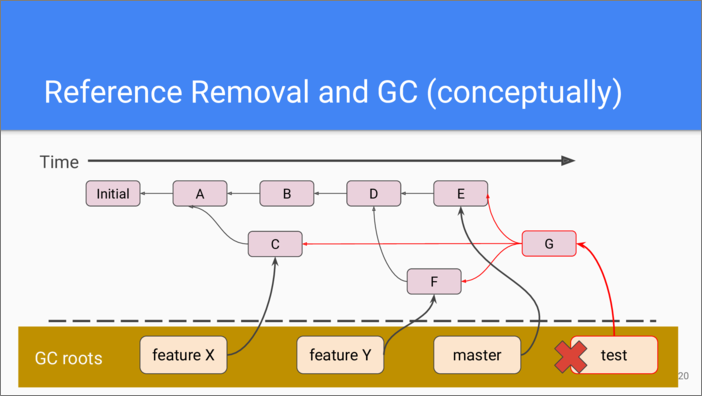
Since references are used by humans, they constitute garbage collection roots. It is assumed that objects not reachable from the GC roots can be removed with no impact on the users. This is an example of this principle in action—once we remove a reference, all commits and associated trees and blobs, if they are not reachable from any other GC root become garbage and can be removed from the repository.
Note that in real life the references are not the only GC root, and actually forcing Git to remove unlinked commits is more involved. This makes recovering from human mistakes easier.
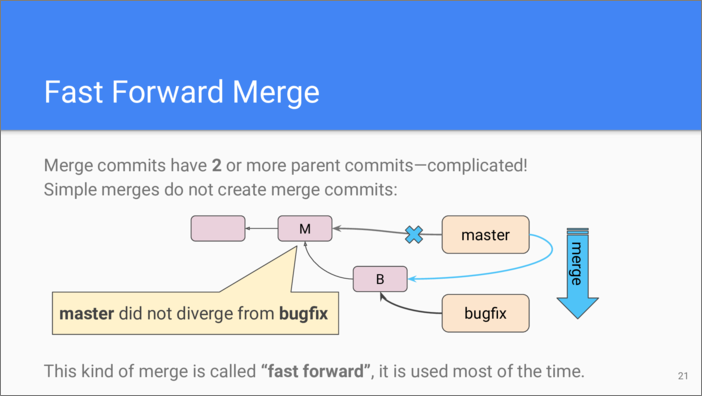
Let’s talk about merge commits. Merges typically occur when we need to integrate changes done on different branches. However, such integration doesn’t always require creating a merge commit with multiple parents.
Let’s consider the situation when “master” is the main development branch, and there is also a branch where some bugfix has been developed. Now we want to have that bugfix in our main branch. Formally, we need to merge “master” and “bugfix” branches. However, if “master” had no changes since the bugfix, instead of creating a new commit Git can simply re-bind “master” branch to point to the same commit as the “bugfix” branch. This is called “fast forward” in Git.
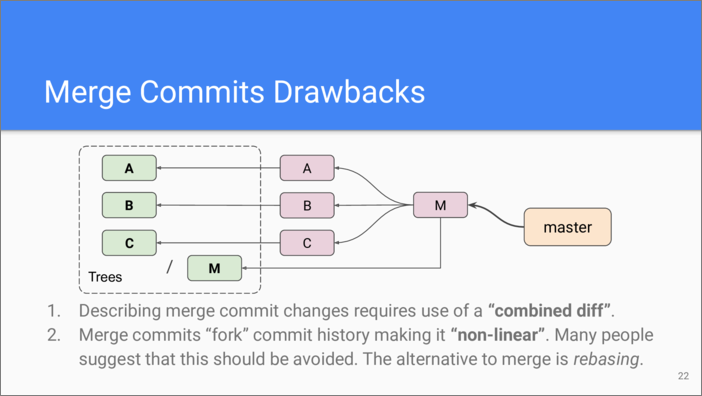
If doing a fast forward merge isn’t possible, Git must create a merge commit. In this example, the commit “M” is a merge commit which has commits “A”, “B”, and “C” as parents. What is the problem with this?
First, there are now 4 trees to deal with. If we want to see how does “M” differ from previous commits, we need either to perform 3 pairwise diffs, or to use what is called “combined diff” which looks more complicated than a usual diff.
Second, when navigating through a commit graph, a merge commit creates a fork. There are several paths to take when going from a merge commit to its ancestors.
That’s why some people advise against using merge commits in their repositories. This policy is similar to coding style—makes no difference to Git, it’s only up to the people who use it. The alternative to merge commits is rebasing. In this example, instead of creating the merge commit, we could take all the distinct changes from each of those branches and create new commits with the same changes but lined up one after another.
We are at the end of the first part of the talk. Let’s recall what we have learned.
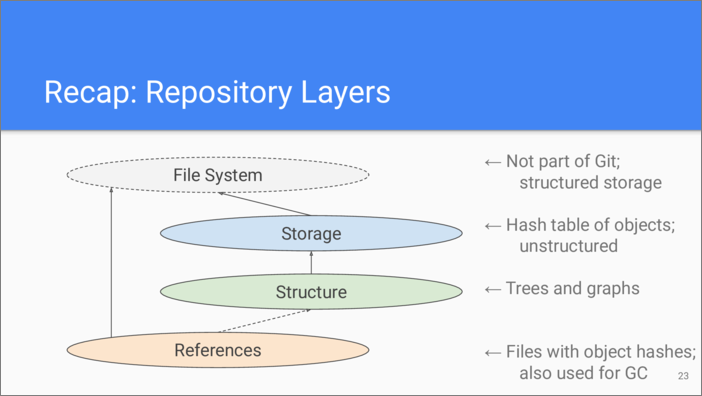
First, recap the layers that comprise a Git repository. The foundation of all is the file system. It is used by the storage layer to store the contents of objects. File system structure is used to find any object by its hash quickly.
Objects can also reference each other using hashes. This forms a structure of the repository. The main structures here are trees and graphs.
Finally, for the convenience of users there is a layer of references that assign human-understandable label to hashes. This layer also directly uses the file system for storage. The labels are in fact file names. The references layer is also used for garbage collection.
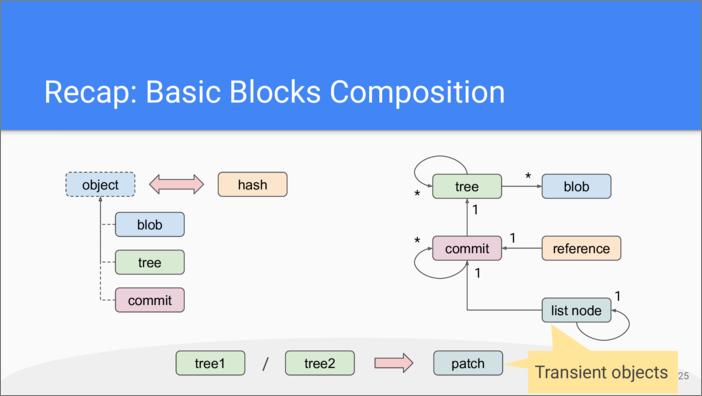
This slide is probably the most important one from the entire talk. If you memorize it, you can understand most of Git help pages. It describes the relationships between the building blocks of the repository. The diagram on the left depicts the storage layer, the diagram on the right depicts upper abstraction layers. On the bottom there is a reminder of how patches do get produced.
UPDATE: Just wanted to clarify that lists and patches are transient objects and they are not stored in the repository.